Александр Охота
Подготовка.
Для начала скачаем и инсталлируем программу — speechanimator_zip.exe. Нужно предварительно войти в курс дела — почитать на досуге страничку помощи программы — «Описание технологии».
Также нам понадобится тестовая модель чайника — teapot.zip.
Для «чистоты эксперимента» создадим файл «Азбука.wav» без карты звуков. Для этого сдублируем файл из комплекта поставки «SpeechAnimator.wav» как «Азбука.wav». После этого удалим карту звуков — меню программы «SpeechAnimator.exe» — сервис — удалить карту звуков из файла… Выбираем файл «Азбука.wav». Получаем сообщение программы — Звуки успешно удалены из файла «Азбука.wav«.
Этап 1. Транскрибирование.
Откроем в программе «SpeechAnimator.exe» файл «Азбука.wav». Будет выдано сообщение — «Файл Азбука.wav не имеет таблицы звуков! Транскрибировать?» Ответим — Да. Далее увидим нечто подобное следующему — Рис.1

Рис.1
Судя по всему, придётся вручную немного подправить работу транскрайбера. Выбирая мышкой звуки по очереди и изменяя их, приводим таблицу морфем приблизительно к следующему виду:
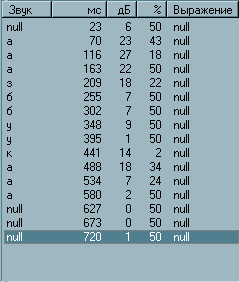
Рис.2
При этом можно выбирать несколько звуков подряд — мышкой в области колонки звуков, либо при помощи клавиши «Shift«.
Прослушать выбранные звуки можно, щёлкнув на кнопке ![]() . Просмотреть результат синхронно со звуком — кнопка
. Просмотреть результат синхронно со звуком — кнопка ![]() . Просмотреть результат синхронно со звуком — кнопка
. Просмотреть результат синхронно со звуком — кнопка . По ней воспроизведение начинается с текущей выбранной позиции.
Будем рендерить при 30 кадрах в секунду. Время между морфемами при глубине 1 — 0,0464 сек, а между кадрами — 0,0333 сек. Поэтому увеличиваем глубину разбиения до 2 (0,0232 сек) — нажимаем кнопочку ![]() . Подтверждаем наше намерение увеличить глубину разбиения.
. Подтверждаем наше намерение увеличить глубину разбиения.
Ну вот, при проигрывании картинка стала заметно лучше! Заметим, что дальнейшее увеличение глубины разбиения в данном случае смысла не имеет, т.к. кадры будут следовать гораздо реже морфем.
На этом транскрибирование можно считать законченным. Жмём кнопку ![]() и выходим из программы «SpeechAnimator.exe». Пока спасибо и на этом.
и выходим из программы «SpeechAnimator.exe». Пока спасибо и на этом.
Этап 2. Привязка базовой модели.
Привязка осуществляется в среде «3D Studio MAX R3.X«. Вообще-то подходит любая версия, был бы модификатор «Skin«. В «3D Studio MAX R2.Х«, как мы знаем, такого и не увидишь. А «Skin» для нашего дела — САМОЕ ТО! Для начала загрузим тестовую модель. Чего-то кривовато выглядит… Ну да ладно. И такая сойдёт.
Нажимаем File-Merge… Ищем наш злосчастный «model.max». Он должен быть в папке инсталляции программы «SpeechAnimator». Далее выбираем загрузку всех объектов — на всякий случай.
Проверяем настройку — «Use Selection Center» и «World» в списке «Reference Coordinate System» — ![]() .
.
Подгоняем всё это дело поближе к «ротику» чайника, простите за выражение. Разворачиваем на 180 градусов относительно оси OZ (World) и градусов на (-20) относительно оси OX (World). Ну, как кому нравится, так и лучше. Самое главное пока, чтобы передняя часть «губ» базовой модели находилась как раз посередине «губ» чайника:
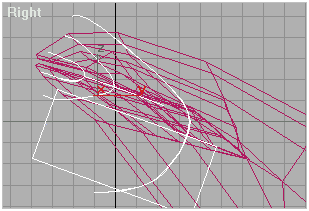
Рис.3
В нашем случае не будем масштабировать базовую модель.
Скроем объекты — «Bottom Mouth» и «Tongue Line» — они нам не понадобятся.
Переходим к по-точечному редактированию линий. Здесь есть очень важный момент. Вся работа программы опирается на тот факт, что положение и ориентация базовых точек всех объектов базовой модели совпадают! Поэтому при операциях с объектами базовой модели нужно за этим следить.
Выберем объект «Static Line«. В режиме «Sub-Object«(и только в нём) перемещаем точки и приводим его примерно к такому состоянию:

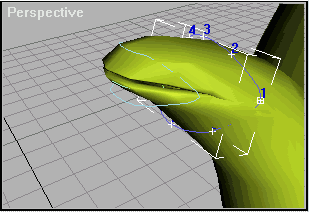
Рис.4
Примерно то же самое проделаем и с объектом «Mouth Line«
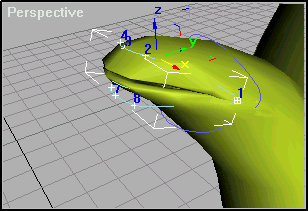
Рис.5
Только в этом случае сдвигаем только точки 1 и 5 «Mouth Line«
Теперь поработаем с «Lips LineTop» и «Lips LineBot«. Сдвигаем, как и прежде, только точки 1 и 5. В процессе сдвига точек парами (а так удобнее) 3D MAX спрашивает, не хотите-ли эти самые точки совместить. Так вот: кто очень хочет, пусть так и делает; а мы — не будем! Их ещё даже нужно немного раздвинуть:
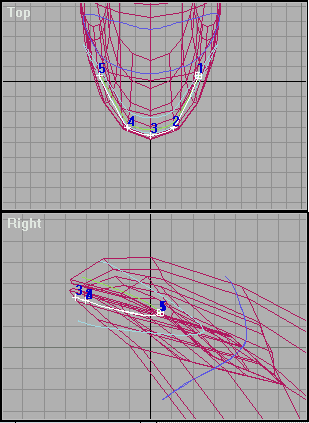
Рис.6
Здесь нужно заметить, что точки 1-1 и 5-5 «Lips LineTop» и «Lips LineBot» желательно разместить как можно ближе друг к другу.
Вроде-бы всё. Выглядит неплохо. С «по-точечным» редактированием линий закончили. Переходим к модификатору «Skin«.
Назначим «Skin» чайнику. Добавим кости «Lips LineTop«, «Lips LineBot«, «Mouth Line«, «Static Line«. Посмотрим, что получилось.
Выберем кость «Static Line«. Перейдём в режим «Sub-Object» модификатора. Включим флажок «Color VerticesWeights«.

Рис.7
По моему мнению, некоторые точки не стоят такого внимания этой косточки. Они ограничены жёлтой линией.
Включим флажок Filters «Vertices», выберем эти лишние точки и назначим им вес «0».
Примерно такого же эффекта можно достичь, изменяя диаметр «Envelopes«.
Переключимся на кость «Mouth Line«. Здесь тоже не всё в порядке:
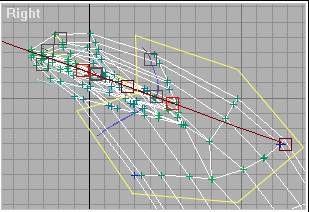
Рис.8
Обнулим вес точек внутри области, ограниченной жёлтой линией
Теперь перейдём к кости «Lips LineTop«:
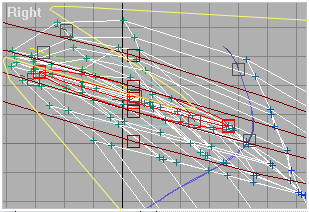
Рис.9
И здесь придётся обнулить вес всех точек в области, ограниченной жёлтой линией. Не нужно пока трогать только часть точек на верхней «челюсти» чайника.
Примерно такая же ситуация с «Lips LineBot«:

Рис.10
Нужно обнулить вес всех точек в области, ограниченной жёлтой линией.
Ну, для начала вроде достаточно.
Этап 3. Генерация анимирующего скрипта.
Вернёмся к программе «SpeecAnimator.exe». Откроем нашу «Азбуку». Нажимаем кнопочку ![]() .
.
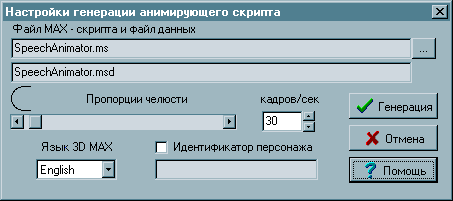
Рис. 11
Выберем кнопкой ![]() , куда будем сохранять итоговые файлы. Пока пропорции челюсти изменять не будем. Нажимаем
, куда будем сохранять итоговые файлы. Пока пропорции челюсти изменять не будем. Нажимаем ![]() , куда будем сохранять итоговые файлы. Пока пропорции челюсти изменять не будем. Нажимаем
, куда будем сохранять итоговые файлы. Пока пропорции челюсти изменять не будем. Нажимаем . Вроде, с этим покончено.
Этап 4. Выполнение скрипта и доводка модели.
 В «3DMAX» выполняем наш скрипт «SpeechAnimator.ms». Много времени это не займёт.
В «3DMAX» выполняем наш скрипт «SpeechAnimator.ms». Много времени это не займёт.
Установим 6 кадр — звук «А». Вроде, всё неплохо выглядит. Только рот можно было и посильнее открыть. Но это мы потом исправим.
Установим 13 кадр — звук «У». Вес точек в прищёчных ямочках должен распределяться примерно так — 50% — «Mouth Line«, 25% — «Lips LineTop«, 25% — «Lips LineBot«.
Если некоторые точки вылезают в неподходящие места, вес их можно назначать прямо в текущем кадре. Выбираем нужную кость, режим «Sub-Object«, и т.д..
![]() В итоге у нас должно неплохо получиться. Вот только рот слабовато открывается… Можно идти двумя путями — увеличить «коэффициент влияния» параметра «Открытие челюсти» — , либо изменить пропорции челюсти при генерации скрипта.
В итоге у нас должно неплохо получиться. Вот только рот слабовато открывается… Можно идти двумя путями — увеличить «коэффициент влияния» параметра «Открытие челюсти» — , либо изменить пропорции челюсти при генерации скрипта.
![]() Пойдём вторым путём. Сгенерируем новый скрипт с такой пропорцией (см. рис.). Может показаться, что нужно было увеличивать длину челюсти, но это не так. Если мы увеличим длину челюсти, в результате рот будет открываться меньше. Это происходит потому, что для достижения заданных пропорций фронтальной проекции рта его и нужно меньше открывать.
Пойдём вторым путём. Сгенерируем новый скрипт с такой пропорцией (см. рис.). Может показаться, что нужно было увеличивать длину челюсти, но это не так. Если мы увеличим длину челюсти, в результате рот будет открываться меньше. Это происходит потому, что для достижения заданных пропорций фронтальной проекции рта его и нужно меньше открывать.
После выполнения нового скрипта подключим «Азбуку» к сцене и сделаем превью для просмотра.
Получили привязанную модель чайника 3DMAX. Сейчас можно заставить его сказать не только «Азбука», а кое-что посолиднее, например, пусть споёт «Город» Б.Г.! На страничке поддержки http://www.chat.ru/~speechanimator/index.htm есть эта песня с картой звуков. Только для работы придётся конвертировать файл в формат PCM — 22050 Гц. Для этого можно использовать встроенный конвертер программы.
Желаю успехов в использовании данной технологии!
С уважением, разработчик, Александр Охота.
hunt@perm.raid.ru